Pythonでピボットテーブル:Jupyter Notebook、pivottablejs利用法
Pythonによるデータ解析では下記のライブラリがよく使われます。
| ライブラリ | 説明 |
|---|---|
| pandas | データ操作を行うライブラリ。データを1次元(Series)と2次元(Dataframe)のオブジェクトとして利用 |
| NumPy | 高速な数値計算を行うライブラリ。サイズの大きい行列・ベクトルの計算を高速に行える |
| matplotlib | グラフ描画を行うライブラリ。棒グラフや折れ線グラフ、ヒストグラムや複数のグラフをまとめて描画可能 |
| scipy | 数学や工学向けの数値計算ライブラリ |
| scikit-learn | 機械学習ライブラリ。クラスタリングや機械学習アルゴリズムとサンプル用のデータセットを備える |
加えて、ブラウザ上で使えるプログラム実行環境である「Jupyter Notebook(旧: ipython notebook)」というアプリケーションがよく用いられます。
「Jupyter Notebook(旧: ipython notebook)」では、ノートブックと呼ばれるドキュメントを作成し、プログラムの記述と実行、メモの作成、保存と共有などをブラウザ上で行うことができます。
スポンサードリンク
このライブラリと「pivottablejs」を使って、Excelのようなピボットテーブルを作る方法をまとめています。
データは青果物情報センターのサンプルCSVを利用(UTF-8に変換)しています。
Pythonを利用したことがない人は、インストール手順のページを見て下さい。
Jupyter Notebook、pivottablejsのインストール方法
Jupyter NotebookはShellのようなものであり、インタプリタ環境で使うものです。
Jupyter(旧: IPython)のインストール
パスが通っていなければ、次のように実行します。
$ /c/Python36/Scripts/pip install jupyter
これで完了です。
pivottablejsのインストール
pivottable.jsはもともとjavascriptのパッケージです。
インタラクティブにデータを可視化したり、集計することが可能になります。
pythonではpivottablejsというモジュールを導入することで使用することができます。
インストール方法は次のようになります。
# /c/Python36/Scripts/pip install pivottablejs Collecting pivottablejs
Jupyter Notebook(旧: ipython notebook)の実行
まずは、Jupyter Notebookのファイル(Notbook)を置くフォルダを作成します。
パスが通っていたら、次のように起動します。
$ cd <Notbookを置くフォルダ> $ jupyter notebook
パスが通っていなければ次のように起動します。
$ cd <Notbookを置くフォルダ> $ /c/Python36/Scripts/jupyter-notebook
これにより、ブラウザが立ち上がり、Jupyter Notebookのホーム画面が「http://localhost:8888/tree」のアドレスで起動します。
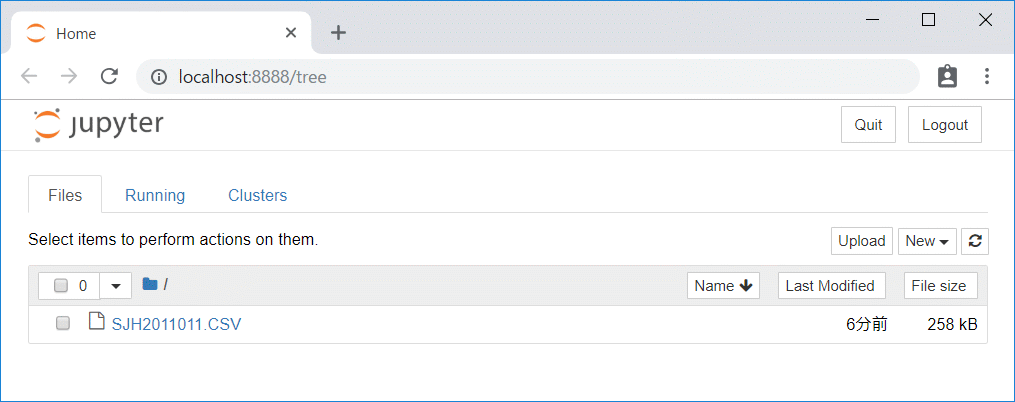
「New」をクリックして「Notebook」から「Python3」を選びます。
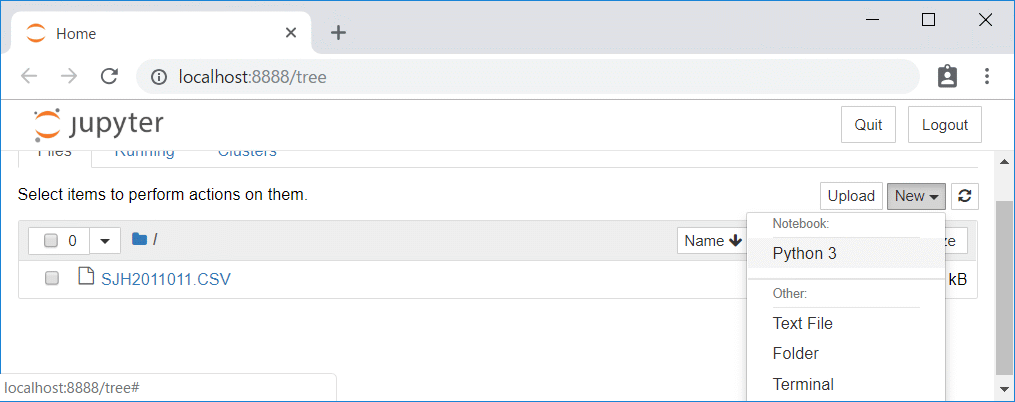
Untitledという空のNootbookが「http://localhost:8888/notebooks/Untitled.ipynb?kernel_name=python3」で作成されると同時に、Notebookの編集画面に移ります。
以降はここで、データ分析を行います。
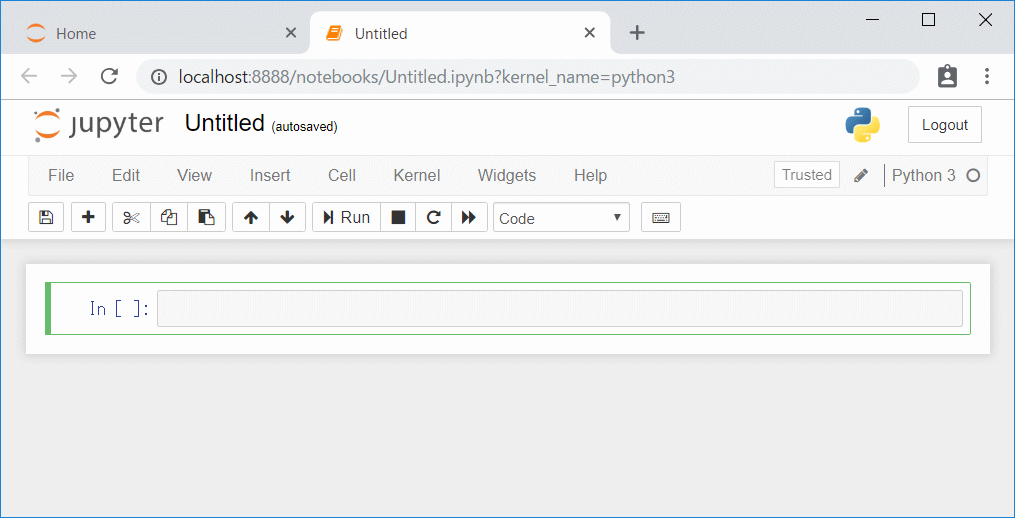
UntitledをクリックしてNotebookの名前を更新しておきましょう。
pivottablejsの使い方基本
Jupyter Notebookを利用したコードの書き方は次のようになります。
import pandas as pd
from pivottablejs import pivot_ui
df = pd.read_csv("./SJH2011011.CSV")
pivot_ui(df)
実行ボタンを押してみましょう(In [数字]の左か、メニューバーから選択できます)。
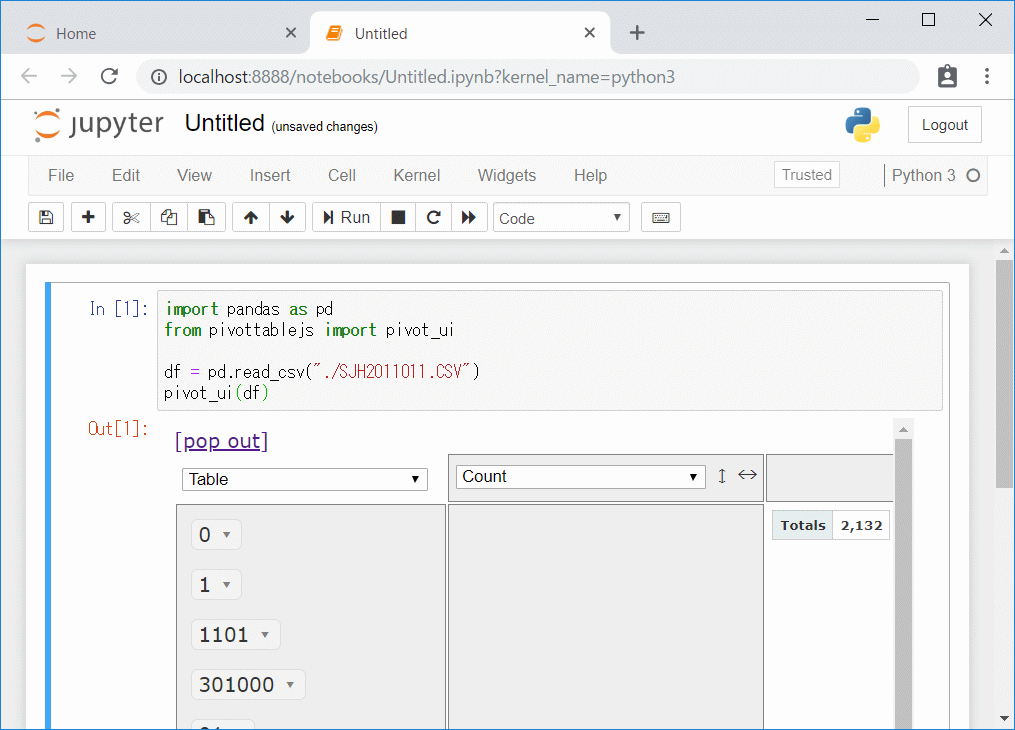
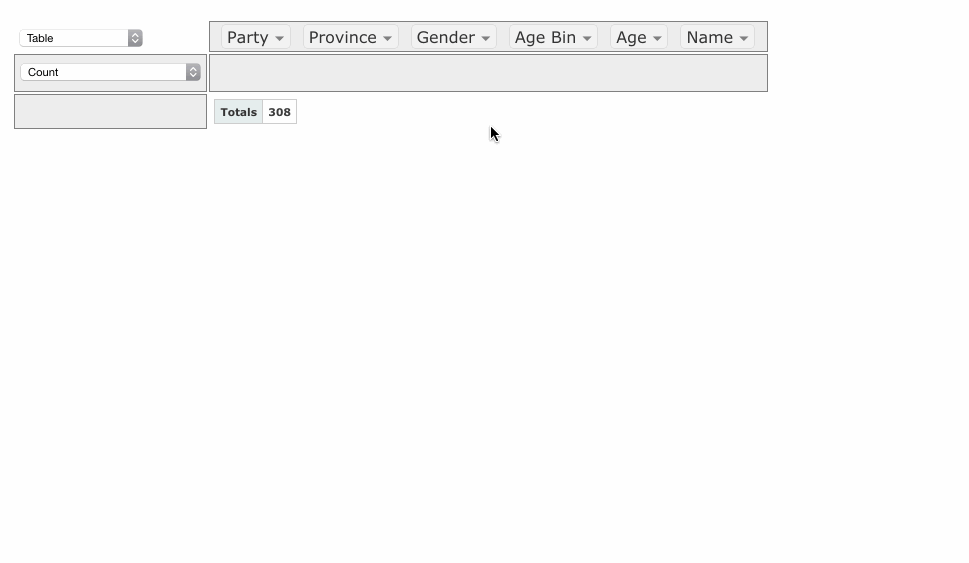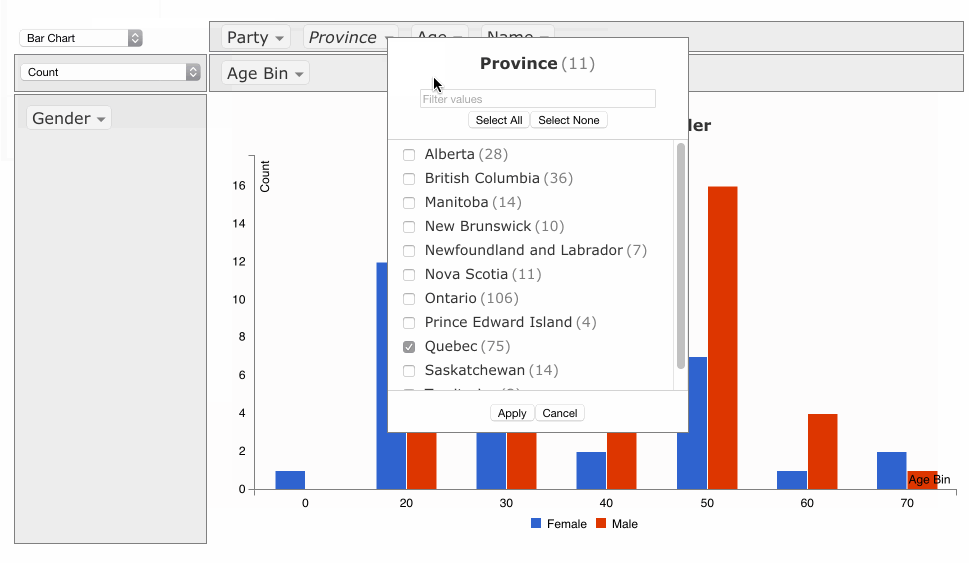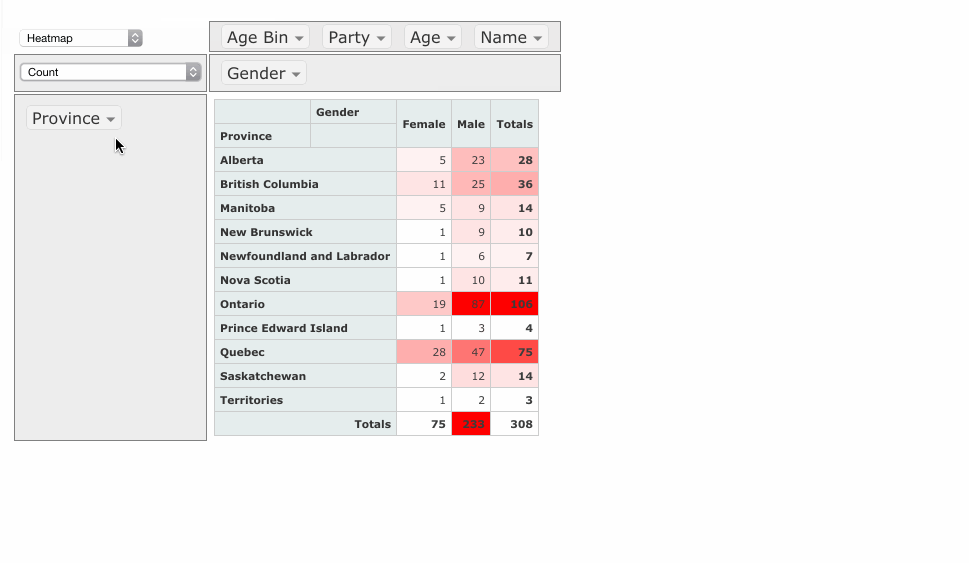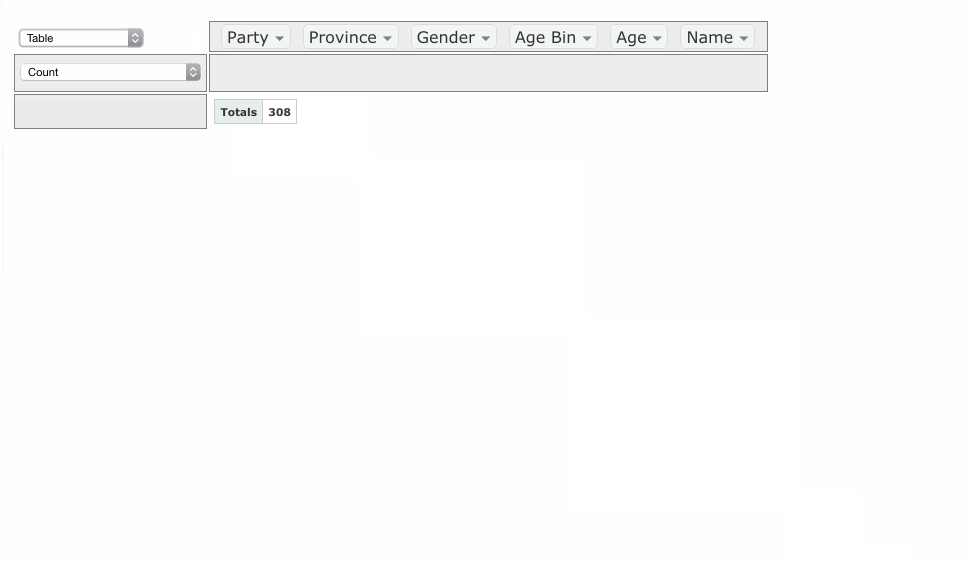
Excelのようなピボットテーブルが表示されました。
この状態で、マウスを使ってExcelのピボットテーブルのように利用します。
[Tips] Jupyter Notebookのセル幅を変えたい
デフォルト状態だと、出力画面が狭いです。
その場合には、「~/.jupyter/custom/custom.css」を作成して次のようなスタイルシートを記載します。
#notebook-container {
width: 95% !important;
}
pivottablejsのpivotUIオプション説明
pivot_ui(pivotUI)の記述は次のようになります。
pivot_ui(input [,options [,overwrite]])
- input:jsonデータ
- options:行列やkeyでの集計方法
- overwrite:データの上書きファイル名指定
それぞれのオプションに指定可能な文字列をまとめます。
詳しくは「公式ページ(英語)]]を参照ください。
pivot_ui の optionsに指定可能な文字列
| 指定可能なKey | 説明 |
|---|---|
| rows | 行に自動指定するKey |
| cols | 列に自動指定するKey |
| vals | 集計欄に自動指定するKey |
| aggregators | どのKeyについて集計をするか |
| aggregatorName | valsで指定した方法をどうやって集計するか |
| renderers | 表示関数の指定 |
| rendererName | テーブルの表示方法を指定 |
| rowOrder | 行の表示を指定("key_a_to_z", "value_a_to_z", "value_z_to_a") |
| colOrder | 列の表示を指定("key_a_to_z", "value_a_to_z", "value_z_to_a") |
| derivedAttributes | 自前の処理結果のカラムを追加 |
| dataClass | レンダリングに渡されるデータクラスのコンストラクタ |
| filter | 各レコードで呼び出され、レンダリング前にレコードを入力から除外する場合はfalse、それ以外の場合はtrueを返す |
| inclusions | レンダリングに含めるレコードを示す属性値の配列 |
| exclusions | レンダリングに含めないレコードを示す属性値の配列 |
| hiddenAttributes | UI上から非表示とするKey |
| hiddenFromAggregators | aggregatorsの引数を省略する属性名 |
| hiddenFromDragDrop | drag&drop UIが表示を省略する属性名 |
| sorters | 属性名で呼び出し、array.sortの引数として使用できる関数を返す |
| onRefresh | レンダラーの更新 |
| menuLimit | ダブルクリックメニューに表示する最大値の数(50) |
| autoSortUnusedAttrs | 未使用の属性がUIでソートされているかどうかを制御する(false) |
| unusedAttrsVertical | 水平方向のデフォルトではなく、未使用の属性が垂直に表示されるかどうかを制御 |
| showUI | drag&drop UIが表示されるかどうかを制御 |
| rendererOptions | レンダラーのオプション |
| localeStrings | UI表示用文字列 |
例として、デフォルト値を記載すると次のようなフォーマットになります。
pivot_ui(df,
cols = [],
rows = [],
vals = [],
derivedAttributes = {},
hiddenAttributes = [],
hiddenFromAggregators = [],
hiddenFromDragDrop = [],
menuLimit = 500,
rowOrder = "key_a_to_z",
colOrder = "key_a_to_z",
exclusions = {},
inclusions = {},
unusedAttrsVertical = 85,
autoSortUnusedAttrs = False,
showUI = True,
sorters = {},
inclusionsInfo = {},
aggregatorName = "Count",
rendererName = "Table"
)
aggregatorName として指定可能な文字列
| オプション名 | 説明 |
|---|---|
| count | レコードの総数 |
| countUnique | valsで指定した値の一意なデータ総数 |
| listUnique | valsで指定した値の一意なものをカンマで区切ったリストで表示 |
| sum | valsで指定した値の合計 |
| intSum | valsで指定した値の合計の小数点無し |
| average | valsで指定した値の平均 |
| sumOverSum | ある値xの和をある値yで割った値 |
| sumAsFractionOfTotal | Total(行列)を100%としたときの合計比率 |
| sumAsFractionOfRow | Total(行)を100%としたときの合計比率 |
| sumAsFractionOfCol | Total(列)を100%としたときの合計比率 |
| countAsFractionOfTotal | Total(行列)を100%としたときのカウント比率 |
| countAsFractionOfRowl | Total(行)を100%としたときのカウント比率 |
| countAsFractionOfRow | Total(列)を100%としたときのカウント比率 |
rendererName オプション
| オプション名 | 説明 |
|---|---|
| Table | 通常のテーブル |
| Table Barchart | セル内に棒グラフ |
| Heatmap | ヒートマップ |
| Row Heatmap | 行基準のヒートマップ |
| Col Heatmap | 列基準のヒートマップ |
| Horizontal Bar Chart | 水平棒グラフ |
| Horizontal Stacked Bar Chart | 水平積み上げ棒グラフ |
| Bar chart | 棒グラフ |
| Stack Bar Chart | 積み上げ棒グラフ |
| Line chart | 線グラフ |
| Area chart | 面グラフ |
| Scatter Chart | 散布図 |
| Treemap | カーペットチャート |
| TSV Export | Tsv形式の出力 |
スポンサードリンク
各種サンプル紹介
HTMLの出力
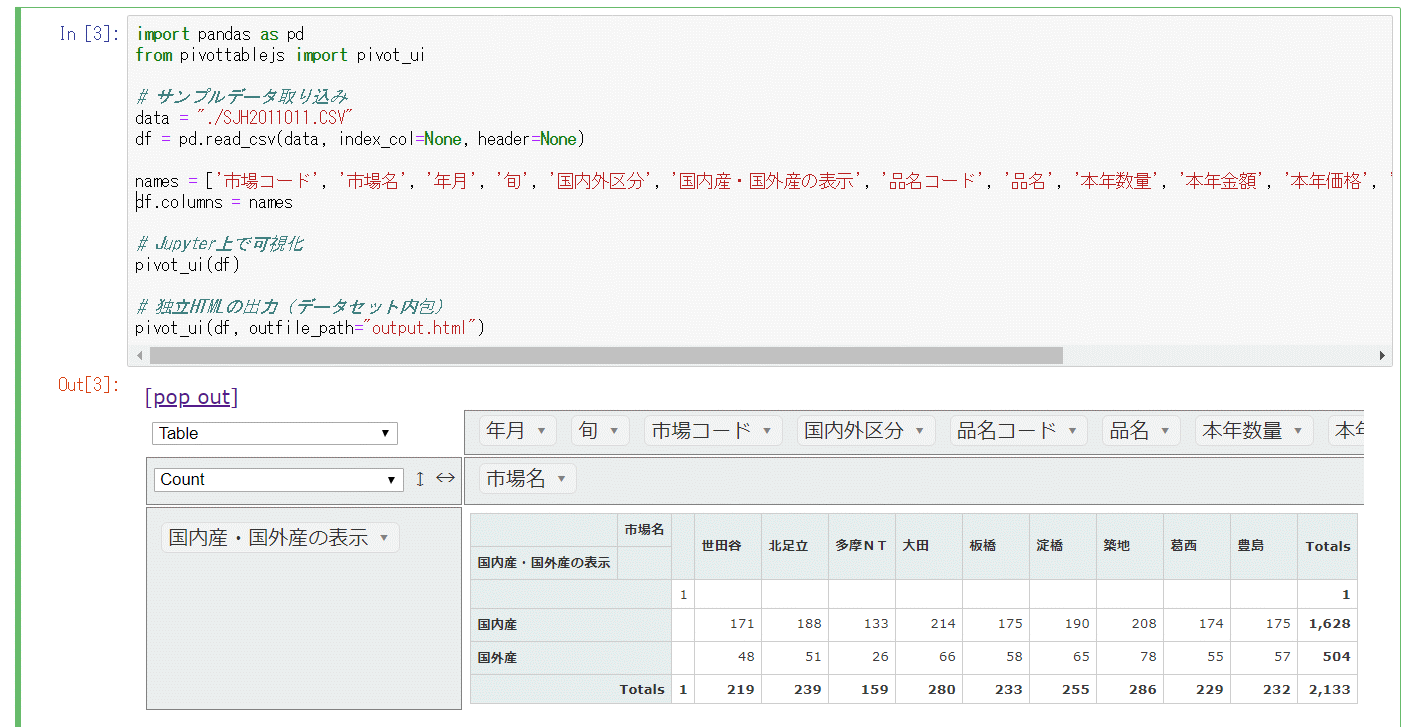
import pandas as pd from pivottablejs import pivot_ui # サンプルデータ取り込み data = "./SJH2011011.CSV" df = pd.read_csv(data, index_col=None, header=None) names = ['市場コード', '市場名', '年月', '旬', '国内外区分', '国内産・国外産の表示', '品名コード', '品名', '本年数量', '本年金額', '本年価格', '前年数量', '前年金額', '前年価格', '終了マーク'] df.columns = names # Jupyter上で可視化 pivot_ui(df) # 独立HTMLの出力(データセット内包) pivot_ui(df, outfile_path="output.html")
【結果】
[番外] Irisを使ったデータ分析
機械学習のライブラリ「scikit-learn」には実験用に7つのデータ・セットが付属しています。
| データ | 内容 | 用途 |
|---|---|---|
| Boston house-prices | ボストン市の地域別住宅価格データ | 回帰向き |
| Breast cancer | 乳がん患者の診断データ | 分類向き |
| Diabetes | 糖尿病患者の診断データ | 回帰向き |
| Digits | 手書き数字のデータ | 分類向き |
| Iris | アヤメの計測データ | 分類向き |
| Linnerrud | 成人男性の生理的特徴と運動能力のデータ | 回帰向き |
| Wine | ワインの成分データ | 分類向き |
基本的には機械学習向けのデータ・セットですが、データ分析・統計解析の練習にも使えます。
import pandas as pd from pivottablejs import pivot_ui # サンプルデータ取り込み data = "https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv" df = pd.read_csv(data, index_col=None, header=None) names = ['Sepal.Length', 'Sepal.Width', 'Petal.Length', 'Petal.Width', 'Species'] df.columns = names # Jupyter上で可視化 pivot_ui(df) # 独立HTMLの出力(データセット内包) pivot_ui(df, outfile_path="iris.html")
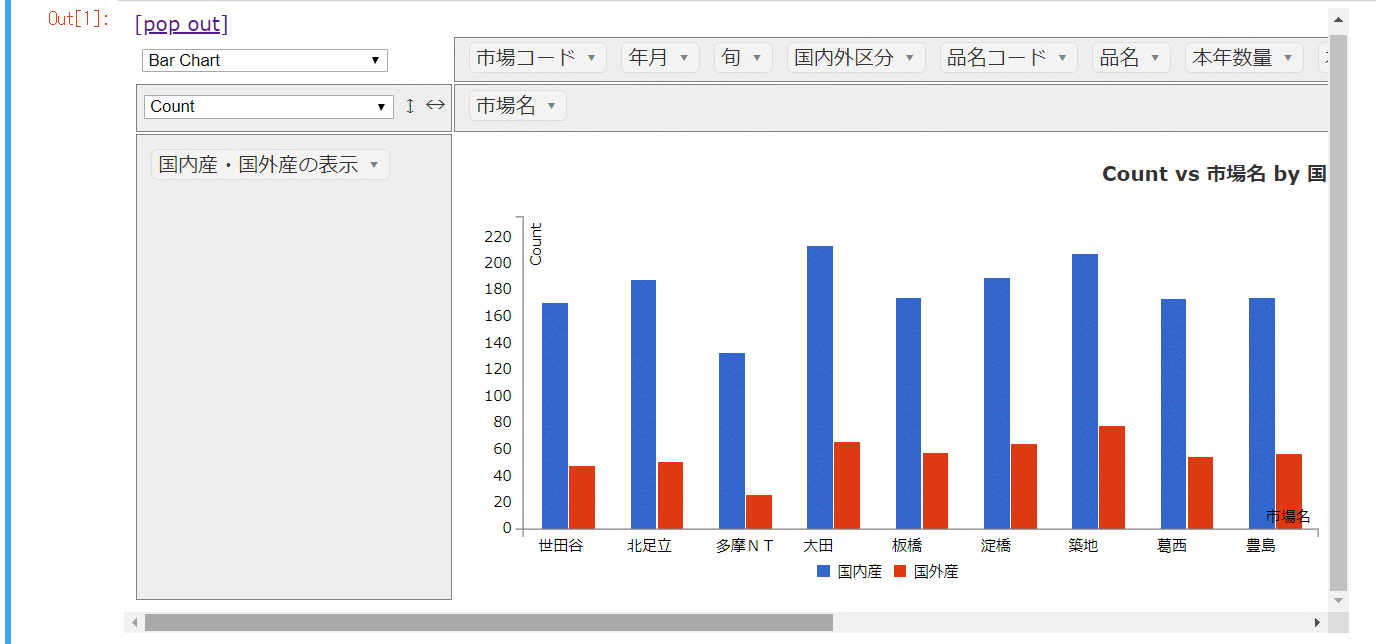
フィルタして棒グラフを表示する
inclusions/exclusions を利用すれば、ピボットテーブル上で表示したいパラメーターだけを選択できます。
import pandas as pd
from pivottablejs import pivot_ui
df = pd.read_csv("./SJH2011011.CSV", index_col=None, header=None)
names = ['市場コード', '市場名', '年月', '旬', '国内外区分', '国内産・国外産の表示', '品名コード', '品名', '本年数量', '本年金額', '本年価格', '前年数量', '前年金額', '前年価格', '終了マーク']
df.columns = names
pivot_ui(df)
# 独立HTMLの出力(データセット内包)
pivot_ui(df,
cols= ["市場名"],
rows= ["国内産・国外産の表示"],
rendererName= "Bar Chart",
inclusions = {
'国内産・国外産の表示': ['国内産', '国外産'],
}
)
【結果】
スポンサードリンク